Setting up a Python venv

At work recently I had a PR open for changing the output of a SQL query to the OSS version of the database we're building and part of that was outputting data in the Apache Parquet format. To validate this worked I had my integration tests in Rust, but I wanted to also check that it worked in another language. One of the benefits of using an open standard in your product is interoperability. With that I wanted to try out pandas to make sure it worked in a non Rust implementation since polars uses the same libraries we use under the hood. My exposure to Python has been running scripts that use the standard library. This means I hadn't stepped into the world of Python environment management and it's reputation had preceded itself for me:
I knew I had to step into it at some point and this seemed like a good time to dip my toes in. Surprisingly it was not that hard! I wanted to write down the steps below both for future me to reference and for anyone else trying to get started with venv.
The Code and The venv
This was the script I wrote in a file called read.py in it's own directory called parquet_read
import pandas as pd
data = pd.read_parquet(path = "test.parquet")
print(data.to_json())Pretty simple as far as code goes, I just wanted to verify I wasn't creating garbled output. I wasn't planning on operating on it or doing anything else. Here was the requirements.txt file which listed all of the libraries I needed to import:
pandas
pyarrowpyarrow was an optional dependency of pandas that I needed in order to read the parquet file into a pandas DataFrame.
❯ pip install -r requirements.txt
error: externally-managed-environment
× This environment is externally managed
╰─> To install Python packages system-wide, try apt install
python3-xyz, where xyz is the package you are trying to
install.
If you wish to install a non-Debian-packaged Python package,
create a virtual environment using python3 -m venv path/to/venv.
Then use path/to/venv/bin/python and path/to/venv/bin/pip. Make
sure you have python3-full installed.
If you wish to install a non-Debian packaged Python application,
it may be easiest to use pipx install xyz, which will manage a
virtual environment for you. Make sure you have pipx installed.
See /usr/share/doc/python3.11/README.venv for more information.
note: If you believe this is a mistake, please contact your Python installation or OS distribution provider. You can override this, at the risk of breaking your Python installation or OS, by passing --break-system-packages.
hint: See PEP 668 for the detailed specification.Since I was using the system wide install I couldn't use pip. It did give some helpful information to work with and told me exactly what I needed to do and so I did:
❯ ls
read.py requirements.txt test.parquet
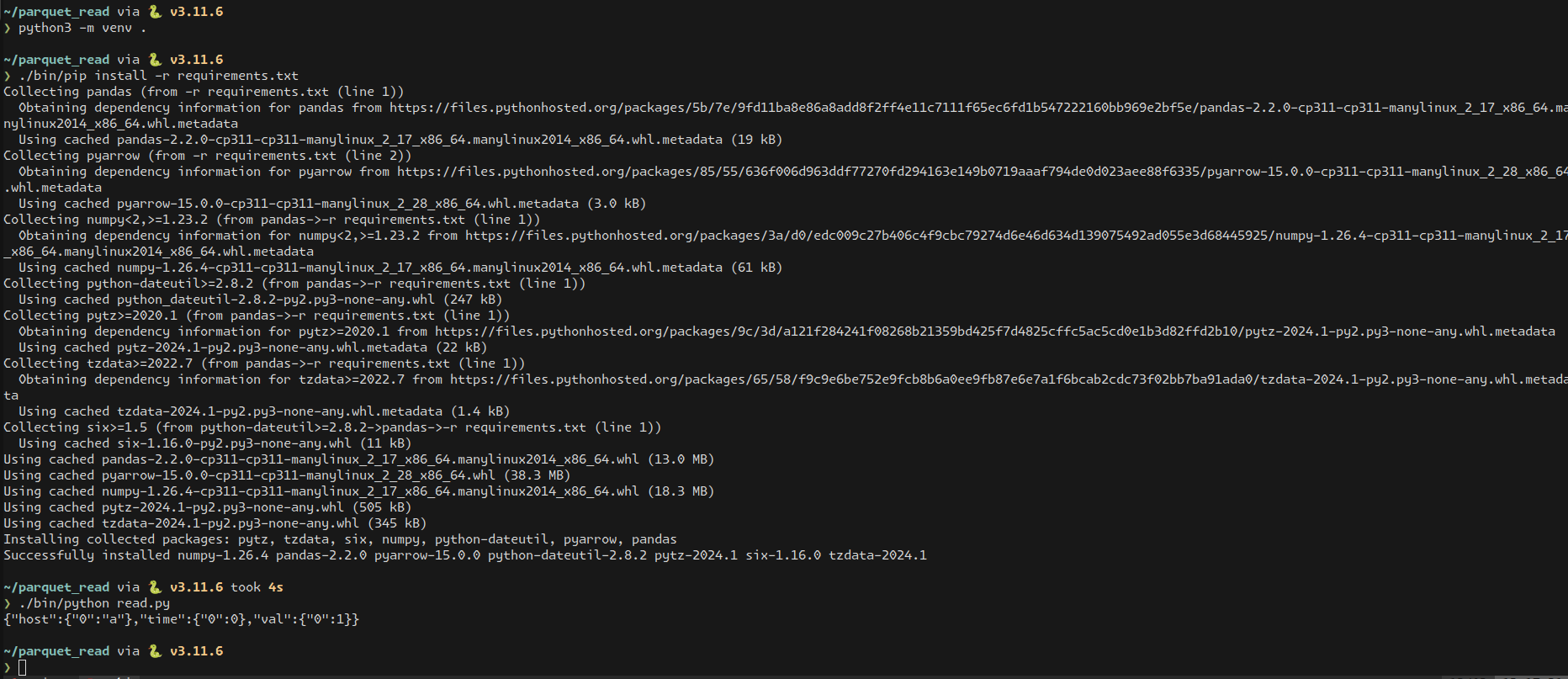
❯ python3 -m venv .
❯ ls
bin include lib lib64 pyvenv.cfg read.py requirements.txt test.parquetIt added a new bin, include, lib, lib64, and pyvenv.cfg file which was all I needed for the virtual environment. Then it was a matter of using the correct pip and python interpreter to run the script:
❯ ./bin/pip install -r requirements.txt
Collecting pandas (from -r requirements.txt (line 1))
Obtaining dependency information for pandas from https://files.pythonhosted.org/packages/5b/7e/9fd11ba8e86a8add8f2ff4e11c7111f65ec6fd1b547222160bb969e2bf5e/pandas-2.2.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata
Using cached pandas-2.2.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (19 kB)
Collecting pyarrow (from -r requirements.txt (line 2))
Obtaining dependency information for pyarrow from https://files.pythonhosted.org/packages/85/55/636f006d963ddf77270fd294163e149b0719aaaf794de0d023aee88f6335/pyarrow-15.0.0-cp311-cp311-manylinux_2_28_x86_64.whl.metadata
Using cached pyarrow-15.0.0-cp311-cp311-manylinux_2_28_x86_64.whl.metadata (3.0 kB)
Collecting numpy<2,>=1.23.2 (from pandas->-r requirements.txt (line 1))
Obtaining dependency information for numpy<2,>=1.23.2 from https://files.pythonhosted.org/packages/3a/d0/edc009c27b406c4f9cbc79274d6e46d634d139075492ad055e3d68445925/numpy-1.26.4-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata
Using cached numpy-1.26.4-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (61 kB)
Collecting python-dateutil>=2.8.2 (from pandas->-r requirements.txt (line 1))
Using cached python_dateutil-2.8.2-py2.py3-none-any.whl (247 kB)
Collecting pytz>=2020.1 (from pandas->-r requirements.txt (line 1))
Obtaining dependency information for pytz>=2020.1 from https://files.pythonhosted.org/packages/9c/3d/a121f284241f08268b21359bd425f7d4825cffc5ac5cd0e1b3d82ffd2b10/pytz-2024.1-py2.py3-none-any.whl.metadata
Using cached pytz-2024.1-py2.py3-none-any.whl.metadata (22 kB)
Collecting tzdata>=2022.7 (from pandas->-r requirements.txt (line 1))
Obtaining dependency information for tzdata>=2022.7 from https://files.pythonhosted.org/packages/65/58/f9c9e6be752e9fcb8b6a0ee9fb87e6e7a1f6bcab2cdc73f02bb7ba91ada0/tzdata-2024.1-py2.py3-none-any.whl.metadata
Using cached tzdata-2024.1-py2.py3-none-any.whl.metadata (1.4 kB)
Collecting six>=1.5 (from python-dateutil>=2.8.2->pandas->-r requirements.txt (line 1))
Using cached six-1.16.0-py2.py3-none-any.whl (11 kB)
Using cached pandas-2.2.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (13.0 MB)
Using cached pyarrow-15.0.0-cp311-cp311-manylinux_2_28_x86_64.whl (38.3 MB)
Using cached numpy-1.26.4-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (18.3 MB)
Using cached pytz-2024.1-py2.py3-none-any.whl (505 kB)
Using cached tzdata-2024.1-py2.py3-none-any.whl (345 kB)
Installing collected packages: pytz, tzdata, six, numpy, python-dateutil, pyarrow, pandas
Successfully installed numpy-1.26.4 pandas-2.2.0 pyarrow-15.0.0 python-dateutil-2.8.2 pytz-2024.1 six-1.16.0 tzdata-2024.1
❯ ./bin/python read.py
{"host":{"0":"a"},"time":{"0":0},"val":{"0":1}}And it just worked! I thought it was really cool to just install a few things into a sand boxed env and run the code and just see it do what I expected it to do was neat and with an interoperable format output from my own code.
Conclusion
Setting up a venv for python was pretty easy. I'm sure there are gotchas that I don't know about since I'm not deeply embedded in the python ecosystem, but in terms of setting it up it wasn't hard and the error message told me exactly what I needed to do in order for my code to work. I could definitely see myself writing far more complex scripts in python for my day to day usage rather than the amalgamation of bash I have stored on my computer given the nice experience. I couldn't ask for better given it was something that I had only heard of how bad it could be through the grape vine. It was pretty painless and at least for me it was easier than expected!